Trotse partner
Artikel

Screaming Frog is de bekendste crawler van websites, en uitermate geschikt om technische checks mee uit te voeren. Na enkele minuten crawlen geeft het programma al tientallen optimalisatiepunten, van missende H1’s en 404 fouten tot foutieve HREFlang. Screaming Frog heeft echter nog talloze andere functies, die vele malen dieper gaan dan een simpele tech check. Soms zijn het leuke trucjes zoals zoeken naar UA codes, maar men kan bijvoorbeeld ook de backend van een site scannen. De inzetbaarheid van onze favoriete tool is haast eindeloos, maar hier een leuk overzichtje van enkele nuttige functies en geavanceerde toepassingen.
Er zijn veel tools beschikbaar waarmee je kan kijken of de UA code goed ingesteld staat op een pagina. Dit is belangrijk, want als de UA code niet goed staat, worden de cijfers niet goed doorgemeten in Google Analytics. Deze tools checken de locatie van de UA code echter altijd maar op één pagina. Met Screaming Frog kan je de code checken op alle pagina’s van je website tegelijkertijd, wat twee grote voordelen heeft. Ten eerste bespaart het veel tijd vergeleken met het één voor één checken van de pagina’s. Ten tweede is het veel minder foutgevoelig, daar het nakijken geautomatiseerd wordt.
Als eerste zoek je de UA code van je website op, welke in GA vermeld staat en ook in de broncode van je homepage staat. Vervolgens open je SF en klik je linksboven op ‘Configuration’. Je selecteert ‘Custom’ en vervolgens ‘Search’. Je krijgt vervolgens onderstaand veld te zien, waarin je je UA code plakt. Het is belangrijk om één filter aan te maken waar de pagina’s mét UA code en een filter zónder.

Nu kan je de crawl starten. Als hij klaar is, ga je naar de Custom tab. Deze vind je in het menu rechts, of in het header menu bovenin. Gelukkig, op de site van Traffic Today staat het allemaal goed!

Orphan pages zijn pagina’s die geen inlink hebben. Het is dus onmogelijk om op de pagina te komen door op links op de site te klikken. De enige manier om op een orphan page is te komen is de directe URL in te voeren. Dit maakt het indexeren van deze pagina’s in Google zeer moeilijk. Sterker nog, als de pagina ook niet in je sitemap.xml genoemd staat, wordt de pagina überhaupt niet gezien. Ook als je pagina wel genoemd staat in de sitemap.xml, maar geen interne link heeft, wordt indexatie erg lastig.
Crawlers werken namelijk door op elke link op een pagina te klikken, en dan te kijken waar ze uitkomen. Aangezien de orphan page geen inlink heeft, zal Google-Bot de pagina nooit bereiken, niet crawlen en niet indexeren. De crawler van Screaming Frog werkt op dezelfde manier.
Toch kan SF orphan pages herkennen. Hiervoor moet je flink wat instellen, dus hou je vast.
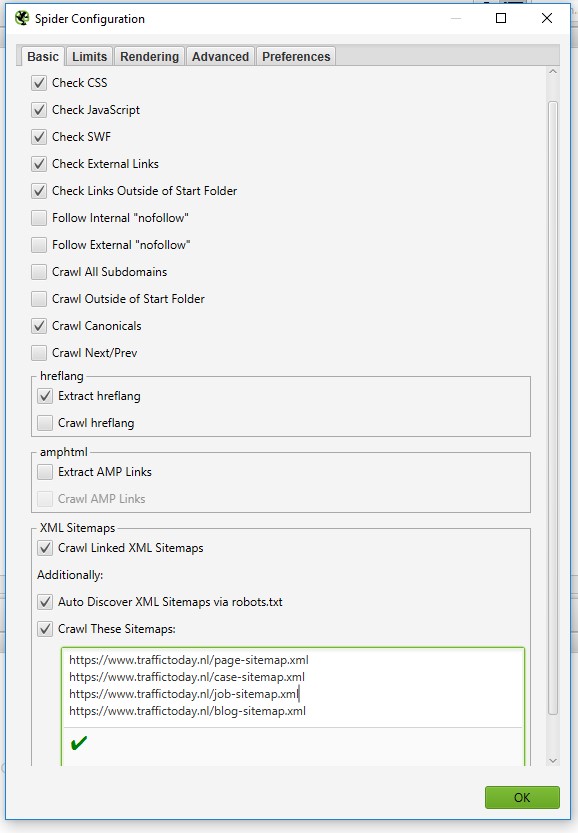
Onder ‘Configuration’ en dan de eerste optie ‘Spider’. Je komt op het onderstaande scherm. Vink ‘Crawl These Sitemaps’ aan, en schrijf je URL’s van al je sitemaps in het vak.
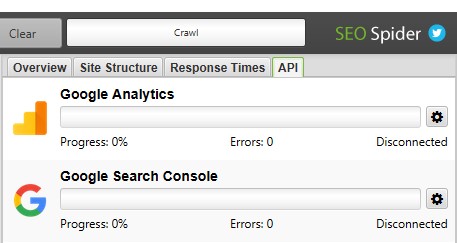
Onder ‘Configuration’ vind je ‘API Access’. Hier kun je GA en GSC verbinden met SF. Hiervoor is het uiteraard wel van belang dat je al toegang had tot beide programma’s van Google.

De reden om de Google programma’s toch toe te voegen is dat orphan pages toch klikken kunnen krijgen uit directie links. Als dat het geval is, wordt dat opgepikt door Google, en verschijnen de URL’s in GSC. Screaming Frog kan de URL’s in dat geval detecteren. Het is wel belangrijk dat je als extra functie bij het instellen van zowel GA als GSC in Screaming Frog het vinkje ‘Crawl new URLs’ aanklikt.

Na je sitemap, Google Analytics en Google Search Console te hebben ingesteld, kan je eindelijk de website crawlen. Rechts kan je in het tabblad ‘API’ zien of GA en GSC goed gecrawled worden.
Sinds Screaming Frog versie 10.0 is er de functie Crawl Analysis, een zeer bruikbare tool die na het crawlen nog eens extra diep in de website duikt.
Bij de configuratie van de Crawl Analysis is het nu belangrijk om de optie ‘Search Console’ aan te vinken.

Nadat de Crawl Analyse gedaan is, kan je eindelijk je Orphan Pages identificeren. Het lijkt omslachtig, maar toch is dit de beste manier. Het is ook zeker de moeite waard, want Orphan Pages kunnen veel waarde toevoegen aan je website op het moment dat ze correct geïntegreerd worden in de site.
Nadat de Crawl Analyse gedaan is, kun je onder de tabbladen van Sitemaps en Search Console de Orphan Pages vinden.
Een HSTS Policy is een instelling op een hosting server die alle verkeer dwingt om via een beveiligde HTTPS koppeling verbinding te maken met een website. Wanneer een website als geheel overgaat van HTTP naar HTTPS, wordt vaak een HSTS redirect gebruikt. Als dit correct wordt geïmplementeerd, is dit veiliger dan een 301 redirect. Een 301 kan namelijk door een kwaadwillend persoon genegeerd worden, en hij kan dan alsnog de HTTP versie van de site bezoeken. Als een pagina een HSTS redirect heeft, is het onmogelijk om nog de oude HTTP versie te bezoeken. Daarom is het belangrijk dat een overgang van HTTP naar HTTPS op elke pagina goed meegenomen wordt. Als er namelijk achteraf alsnog HTTP pagina’s of contentelementen bereikbaar zijn, kun je spreken van een veiligheidsrisico.
Na het eerste bezoek aan een site wordt een HSTS redirect niet afgeschoten vanaf de server, maar al vooraf herkend door de browser. Vanaf het moment dat de site een keer is bezocht, onthoudt de browser dat er een HSTS policy in werking is. Om deze reden is het onmogelijk om de oude HTTP versie van de pagina te bezoeken. Echter, er moet nog steeds een reguliere site-wide 301 redirect geïmplementeerd worden. Dit komt doordat HSTS alleen werkt als de blokkade die afgevuurd wordt en bezoekers verbiedt om de HTTP versie te bezoeken, verzonden wordt over een HTTPS verbinding.
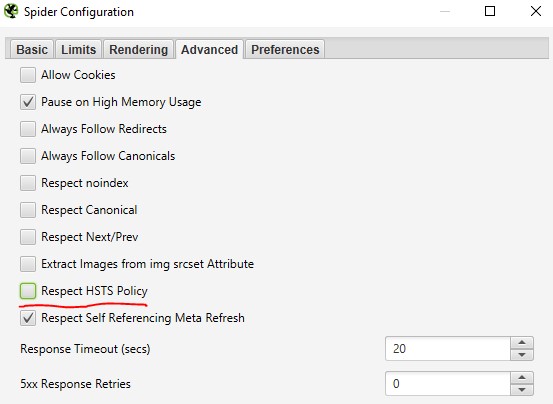
Screaming Frog heeft een functie om de HSTS policy te negeren. Als deze functie is ingeschakeld, wordt gekeken of het achterliggende 301 redirect van HTTP naar HTTPS wel goed werkt.
Dit doe je door in de Spider Configuration het vinkje ‘Respect HSTS Policy’ uit te schakelen.
Screaming Frog crawled een website op zo veel mogelijk dezelfde manier als Google-Bot. Jij kan als website eigenaar een prachtig mooie menustructuur opbouwen, maar als Google hem niet volgt dan werkt het niet.
Met het Crawl Path Report kan je ontdekken via welke links Screaming Frog op een pagina is gekomen. Als dit anders is dan jij wilt, kun je vervolgens actie ondernemen om dit te veranderen.
Je ontdekt het Crawl Path Report door met een rechtermuistoets op een URL te klikken.

Regex oftewel Regular Expressions is een reeks tekens die een zoekpatroon definiëren, voornamelijk voor gebruik voor het zoeken (en vervangen) in bestanden of databases. Regex wordt bijvoorbeeld gebruikt in Google Analytics voor het matchen van URL’s en bij het ondersteunen van ‘Find and replace’ in de meest populaire editors zoals Notepad ++, Brackets, Google Docs en Microsoft Word.
Voorbeeld: reguliere expressie voor een e-mailadres:
^ ([a-zA-Z0-9 _ – .] +) @ ([A-zA-Z0-9 _ – .] +) . ([A-zA -Z] {2,5}) $
De bovenstaande reguliere expressie kan worden gebruikt om te controleren of een bepaalde reeks tekens een e-mailadres is of niet.
Regex is één van de meest krachtigste methodes om je werkzaamheden voor SEO te versnellen. Stel: je hebt een lijst met URL’s en je wilt alleen de domeinnamen van deze lijst overhouden. De HTTP en WWW kun je eenvoudig verwijderen door de ‘search & replace’ functie van je teksteditor, maar hoe verwijder je de bestandsnamen en subfolders wat na de / komt?
Dit is met Regex zeer eenvoudig! Met behulp van de regex-wildcard (/ *) kun je de schuine streep laten verwijderen en ook alles wat daarna komt. Zo heb je met een simpele bewerking een gehele lijst schoongemaakt, waar je handmatig vele uren werk in had gestoken. Dit is een simpel voorbeeld, maar de mogelijkheden met Regex zijn zeer uitgebreid.
Regex is ook te gebruiken in Screaming Frog. In dit artikel behandelen twee mogelijkheden om Regex te gebruiken in samenwerking met Screaming Frog:
Regex is te gebruiken om Screaming Frog aan te geven welke URL’s opgenomen moeten worden in de crawllist en welke output Screaming Frog moet generen. Stel: we willen alle blogs van traffictoday.nl crawlen en als output weergeven.
In dit geval willen we alleen de URL’s die /blog/ bevatten opnemen in onze lijst.
Het volgende vullen we in het venster van ‘include’:
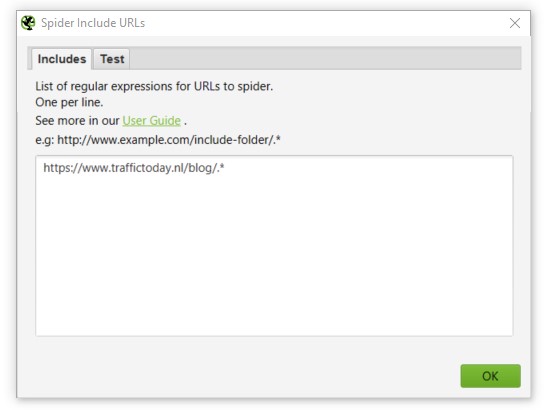
We drukken op ‘OK’ en laten Screaming Frog starten met het crawlen van de website. Dit levert de volgende output op:
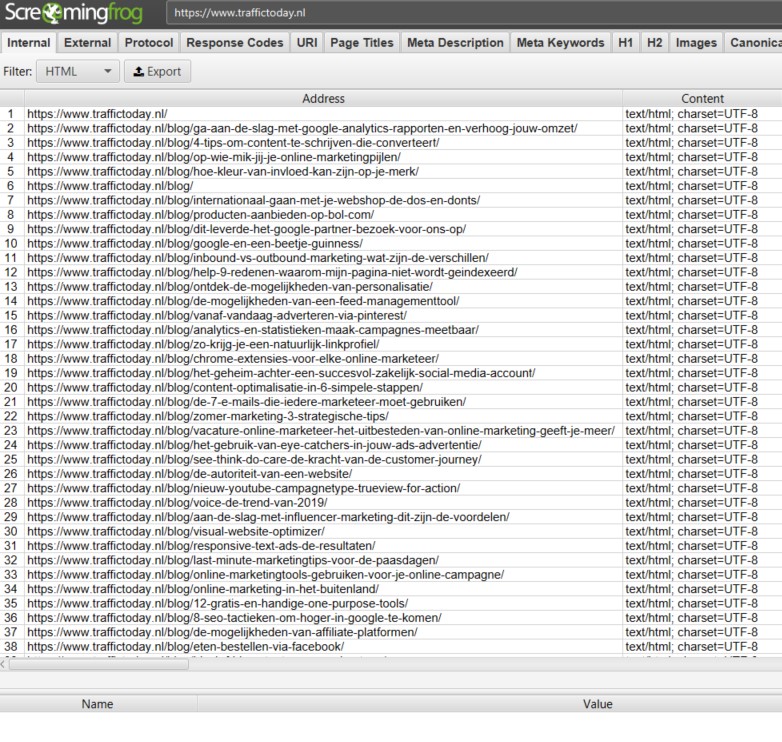
Op deze simpele manier hebben we gezorgd dat alleen de blogberichten als output weergegeven wordt. Regex kun je op deze manier nog voor vele doeleinden gebruiken, zoals: uit / in sluiten van subdomeinen en uit / in sluiten van parameters in URL.
Screaming Frog haalt automatisch veel belangrijke data op zoals; paginatitels, H1-elementen, canonical tags, etc. Maar wat als je andere data uit je crawls wilt halen? Met Custom Extraction en Regex kun je Screaming Frog zo programmeren om ongeveer elk gewenst stukje content of code uit een website te halen. Om deze feature in Screaming Frog te gebruiken ga je onder Configuration naar Custom > Extraction.
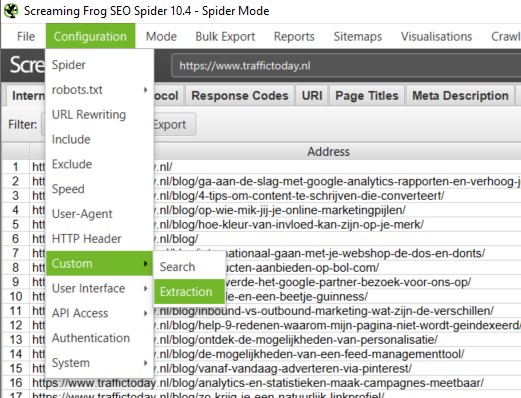
Vervolgens kun je de extraction rules instellen. De volgende zaken zijn in te stellen:
Nadat alles is ingesteld en je de crawl hebt uitgevoerd vind je de data die je hebt opgehaald onder het tabje ‘custom’, waarbij je bij filter ‘extraction’ hebt aangegeven.
Gebruik XPath om een HTML-element van een webpagina te screapen. Als je informatie in een div, span, p, heading-tag of echt elk ander HTML-element wilt scrapen, gebruik dan Xpath.
Google Chrome heeft een functie die het ontdekken van de XPath locatie eenvoudiger maakt. Met behulp van de Inspect-tool kun je met de rechtermuisknop op elk element klikken en de XPath-locatie kopiëren.
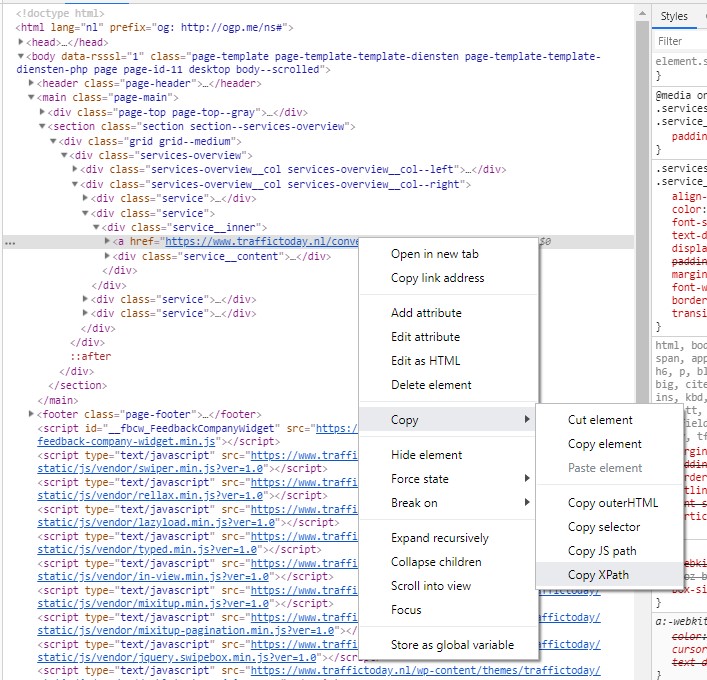
Vervolgens kun je deze locatie invoeren in het venster van Custom Extraction in Screaming Frog en de spider zijn werk laten doen.
Wil je inspiratie opdoen welke zaken je met behulp van Xpath kunt scrapen? Vind hier enkele voorbeelden
In het venster van Custom Extracion kan ook gekozen worden voor Regex. Waar je met behulp van XPath eenvoudig HTML kunt scrapen, is het niet mogelijk om hier JavaScript mee op te halen. Met Regex is het bijvoorbeeld mogelijk om schema markup in JSON format op te halen. Ook is het mogelijk om data uit tracking scripts, zoals een Google Analytics tracking ID op te halen.
Screaming Frog geeft enkele voorbeelden om Regex te gebruiken bij Custom Extraction.
Klik hier voor de voorbeelden die Screaming Frog geeft.
Screaming Frog is een onmisbare tool in het arsenaal van een online marketeer en geeft je eindeloos veel mogelijkheden om websites tot in de kleinste details te analyseren. We hopen dat je door het lezen van dit blog met geavanceerde toepassingen nog meer functionaliteiten ontdekt die je kunt toepassen tijdens je dagelijkse analyse en optimalisatie werkzaamheden!



Ons team staat
voor je klaar


