Trotse partner
Artikel

Duplicate content is een wijdverspreid probleem. Sterker, tot wel 25% van alle pagina’s op het crawlbare web is een duplicaat. Mede om die reden is het dan ook een mythe dat Google websites een penalty geeft voor duplicate content. Maar is het dan wel erg? En zo ja, wat zijn de risico’s?
Dat gaan we beantwoorden in deze blog, want positief is het zeker niet. Allereerst moeten we een scheiding maken tussen interne duplicate content en externe duplicate content. Content die op je eigen site staat kan je vanzelfsprekend gemakkelijker verhelpen dan externe, maar kansloos ben je nooit. In deze blog lees je hoe je duplicate content kan ontdekken, wat de risico’s zijn en wat je eraan kan doen.
Wanneer Google je site crawled en ziet dat twee pagina’s erg op elkaar lijken, kan Google-Bot in de war raken. Vervolgens kiest hij de pagina die volgens Google het meest relevant is om te indexeren, maar dit hoeft helemaal niet de pagina zijn die jij geïndexeerd wilt hebben voor dat keyword. Het gevolg is dus dat er verkeer binnen kan komen op een niet-geoptimaliseerde pagina met een enorm bounce percentage als gevolg.
In het geval dat er twee sterk op elkaar lijkende pagina’s voor hetzelfde keyword geïndexeerd proberen te geraken, spreekt men van interne concurrentie. Een ander woord hiervoor in de SEO wereld is kannibalisatie, daar de pagina’s elkaars relevantie als het ware aanvreten.
Op het moment dat Google wegens de duplicate content in de war is, kan het gevolg hebben voor de ranking van alle pagina’s die voor dit keyword ranken. Sterker nog, in erge gevallen kan het voorkomen dat alle pagina’s uit de index worden gegooid totdat het probleem is opgelost. Een extra stok achter de deur om het snel op te lossen!
Duplicate content kan je website veel schade berokkenen, terwijl het relatief gemakkelijk op te lossen is. Voordat je het probleem echter op kan lossen, moet je de getroffen pagina’s eerst lokaliseren.
Het is erg handig als je je website laat crawlen door een tool die technische fouten kan ontdekken, zoals Semrush, Ahrefs en uiteraard ook Screaming Frog, waar wij een ander blog over geschreven hebben. De eerste hints dat een site te maken heeft met duplicate content is als dezelfde Meta description, pagina titel en H1 telkens terugkomen. Met name als er meerdere URL’s terugkomen die hetzelfde keyword bevatten, is dat een sterke aanwijzing dat we hier te maken hebben met soortgelijke pagina’s.
We nemen een website van een hotel als voorbeeld. Stel, je hebt een hotel in Deventer, en maakt allerlei landingspagina’s aan om meer keywords te hebben en de website beter te laten ranken. De URL’s van deze landingspagina’s zijn als volgt:
Deze URL’s van de landingspagina’s zijn dermate verwant aan elkaar, dat de kans aannemelijk is dat er sprake is van duplicate content. Inspectie van de daadwerkelijke pagina’s moet dat uitwijzen.
Van alle tools die een site crawlen is Ahrefs de favoriet bij deze specifieke taak. Het uitpluizen van meta’s en dergelijke doen alle crawlers wel, maar Ahrefs laat een erg handig en overzichtelijk kaartje zien wanneer er sprake is van duplicate content. Het kaartje laat zien dat er telkens een andere URL wordt geïndexeerd door Google voor één site en voor hetzelfde keyword.
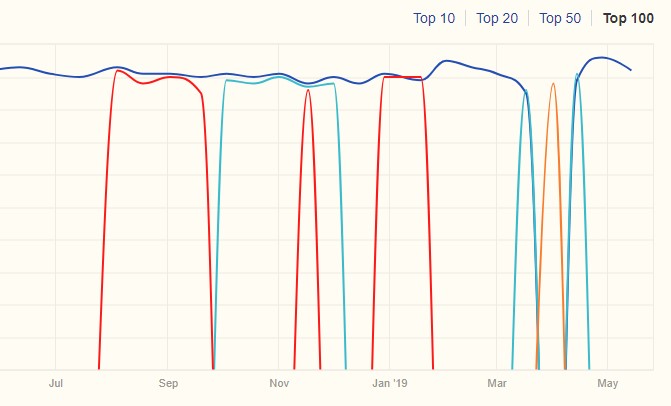
Elke verschillende kleur wijst op een andere URL die voor dezelfde term geïndexeerd wordt. Hier is duidelijk op te zien dat wanneer er een andere URL wordt geïndexeerd voor hetzelfde keyword, een andere URL verdwijnt uit de index.
Google heeft canonicals in het leven geroepen om dit probleem te voorkomen. Met een canonical vertel je Google dat twee pagina’s dermate gelijk aan elkaar zijn dat ze als duplicate gezien worden, en maar één van de twee geïndexeerd moet worden. De waarde van de gecanoncaliseerde pagina wordt overgeheveld naar zijn ‘tweeling’, maar de pagina blijft wel benaderbaar.
Met een 301 redirect verwijs je de ene pagina naar de andere. Met een 301 redirect wordt net zoals bij een canonical de waarde van een pagina overgeheveld naar een andere, maar anders dan bij een canonical blijft de pagina die geredirect wordt niet benaderbaar.
Soms kan het voordelig werken om het duplicate content probleem te verhelpen door simpelweg de content aan te passen. Als je je realiseert dat twee (of meer) pagina’s op dit moment voor hetzelfde keyword ranken, maar dat de pagina ook herschreven kan worden om voor een ander (gerelateerd) keyword te ranken, is dat zeker het overwegen waard. Het kan erg lang duren voordat een volledig nieuwe pagina geïndexeerd wordt, terwijl het veel korter kan duren voordat een bestaande pagina waarvan de content geüpdatet is opnieuw wordt bezocht door Google. Tevens hebben bestaande pagina’s vaak al inlinks van andere pagina’s op de website of zelfs ook al extern.
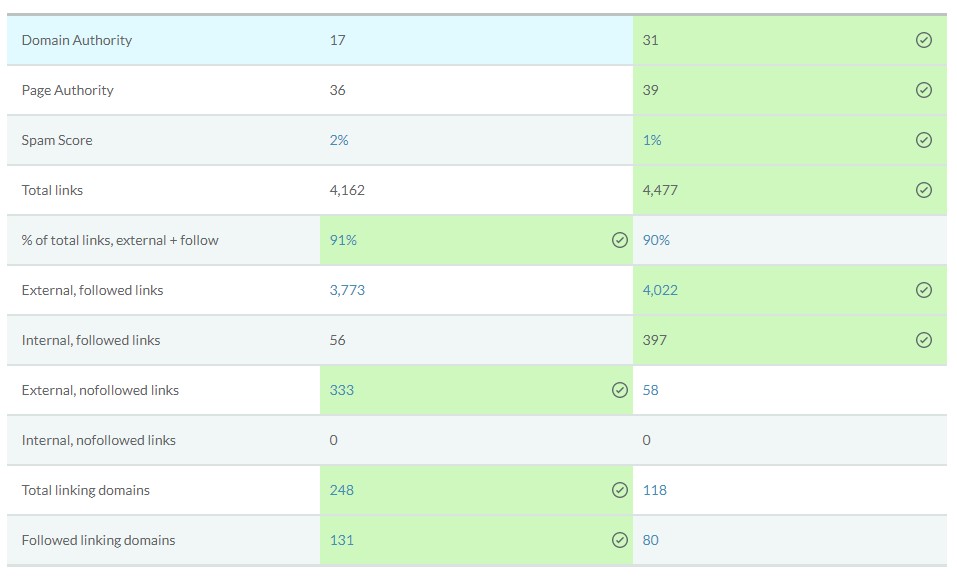
Dit is een veelvoorkomend probleem en vaak is het op het eerste gezicht helemaal niet logisch welke URL het meeste autoriteit heeft en welke juist canoncaliseerd moeten worden. Gelukkig heeft MOZ hier een uitmuntende tool voor, die je in een gemakkelijk overzicht laat zien welke pagina de meeste autoriteit heeft. De tool laat o.a. zien welke pagina de meeste externe en interne links heeft, spam score en meer. Zo is de keuze snel gemaakt!
Een metatag die bijzonder nuttig kan zijn in het omgaan met duplicate content is meta-robots, met de waarden “noindex, follow.” Deze meta-robots-tag worden toegevoegd aan de HTML-kop van elke individuele pagina die moet worden uitgesloten van de index van een zoekmachine.
<p>Algemeen formaat:</p><Head>
<meta name = “robots” content = “noindex, follow”>
Met de tag meta-robots kunnen zoekmachines de links op een pagina crawlen, maar wordt er voorkomen dat ze die links opnemen in hun zoekindexen. Het is belangrijk dat de dubbele pagina nog steeds kan worden gecrawld, ook al vertel je Google dat deze niet moet worden geïndexeerd, omdat Google expliciet waarschuwt voor het beperken van crawltoegang tot dubbele inhoud op je website.) Het gebruik van meta-robots is een bijzonder goede oplossing voor dubbele inhoudsproblemen met betrekking tot paginering.
Een andere mogelijkheid om pagina’s van indexering uit te sluiten is het gebruik van de robots.txt. Hier kunnen pagina’s en hele subfolders worden uitgesloten van indexeren. Dit kun je doen door ‘Dissalow: /paginanaam/’ toe te voegen aan de robots.txt. Op deze geef je aan dat Google deze pagina niet mag opnemen in de zoekindex.
Met Google Search Console kun je het voorkeursdomein van je site instellen (bijvoorbeeld http://jouwwebsite.nl in plaats van http://www.jouwwebsite.nl) en opgeven of Googlebot verschillende URL-parameters anders moet doorzoeken (parameterverwerking).
Afhankelijk van je URL-structuur en de oorzaak van je dubbele inhoudsproblemen, kan het instellen van jouw voorkeursdomein of het afhandelen van parameters (of beide!) Een oplossing bieden.
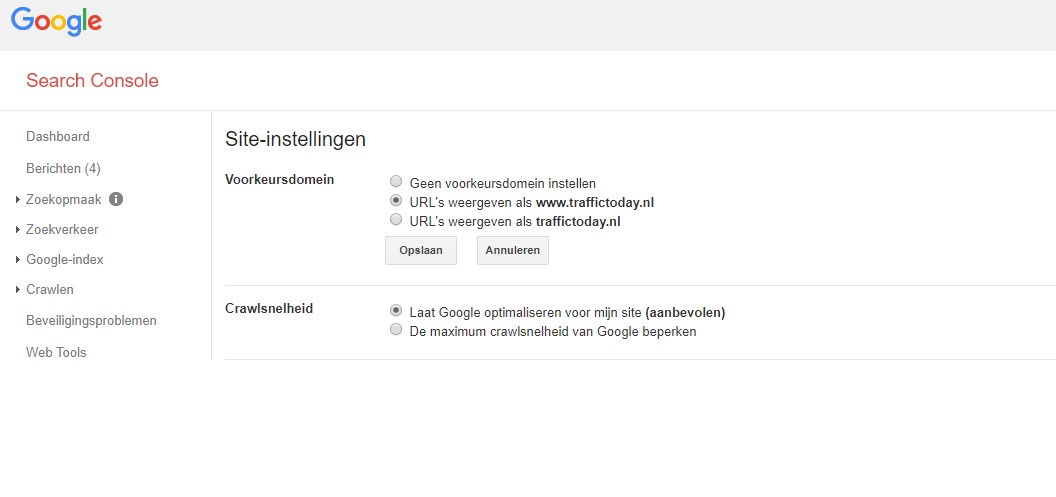
Het belangrijkste nadeel van het gebruik van parameters als primaire methode, is dat de wijzigingen die je aanbrengt alleen voor Google werken. Regels die zijn ingesteld met behulp van Google Search Console, hebben geen invloed op hoe Bing of de crawlers van andere zoekmachines je site interpreteren.
Het kan ongelooflijk frustrerend zijn om tijd en moeite te besteden aan mooie en originele content voor je website en vervolgens erachter te komen dat deze is gedupliceerd door een andere site.
Want als het gaat om website content, kan het stelen (in de vorm van dubbele inhoud) een negatieve invloed hebben op rankings, verkeer en uiteindelijk op conversies. En hoewel het een hopeloze zaak lijkt, kun je er iets aan doen.
Niet alleen het bewust stelen en overnemen van content kan voor externe duplicatie zorgen, maar ook automatische scrapers of content syndicatie kunnen tot meerdere kopieën van jouw content zorgen.
Het doel van Google is om gebruikers de best mogelijke gebruikerservaring te bieden. Om dit te bereiken, willen ze niet dat hun gebruikers identieke informatie zien die binnen dezelfde zoekresultaten wordt herhaald. Dit betekent dat ze met het bestaan van identieke informatie moeten beslissen welke versie van de inhoud ze in hun zoekresultaten willen weergeven.
Maar waarom kan Google niet vertellen welke inhoud het origineel is? Je zou denken dat ze moeten weten welke pagina als eerste werd geïndexeerd en behandel die pagina vervolgens als het origineel. Helaas blijkt dit in de praktijk niet zo te werken. Uit ervaring weten we dat er vaak rankings verloren gaan, nadat content is gekopieerd.
We gebruiken Copyscape, wat een geweldige tool is voor het vinden van externe duplicate content. Je plakt eenvoudig de URL’s in het het zoekvak en voilà – je ziet alle pagina’s op internet met inhoud die net iets te veel op de jouwe lijkt (of helemaal identiek is). Een andere handige tool is Grammarly. Deze werkt ook erg fijn en gemakkelijk
Hoewel dit enige tijd kan duren, is dit de meest effectieve manier om duplicate content te vinden zonder het gebruik van een online tool. Het is eigenlijk heel simpel – je hoeft alleen maar delen van je inhoud in de Google-zoekbalk te plakken (niet meer dan 1-2 zinnen) en op Enter te klikken. Je kunt ook aanhalingstekens aan de zoekopdracht toevoegen om inhoud te vinden die volledig identiek is.
Deze stap lijkt misschien een beetje zwak, maar het is belangrijk om de website met duplicate content te benaderen. Ten eerste zijn de verantwoordelijken misschien niet eens op de hoogte van het probleem, wat betekent dat het bijvoorbeeld de fout kan zijn van een luie tekstschrijver. Ten tweede, zelfs als de verantwoordelijke personen jouw inhoud opzettelijk hebben gedupliceerd, kan het zijn dat ze geen benul hebben van de mogelijke negatieve effecten.
Probeer in je mail contact duidelijk te zijn om welke inhoud het gaat en wat je verwijderd wilt hebben. Ook is het slim om concreet te zijn hoe lang diegene de tijd heeft om het er af te halen en wat de consequenties zullen zijn als ze het verzoek negeren.
Door een verzoek in te dienen op grond van de Digital Millennium Copyright Act, vraag je Google om de pagina’s met gedupliceerde inhoud uit de Google-index te verwijderen.
Dus nee, ze kunnen de inhoud niet echt van de duplicerende website verwijderen, maar als deze niet in de Google-index voorkomt, is deze zo goed als verdwenen (en, belangrijker nog, deze heeft geen invloed meer op je rankings).
Je kunt dit doen op deze speciaal ingerichte pagina van Google. Hier kun je alle stappen volgen om zo een succesvol verzoek bij Google in te dienen om content te verwijderen. In onze ervaring reageert Google meestal binnen 4 dagen. Dat is dus erg snel al.
Als je een extra stukje beveiliging wilt toevoegen tegen contentscrapers automatisch content stelen en verspreiden, is het verstandig om een self referential rel=canonical link toe te voegen aan jouw bestaande pagina’s. Dit is een canonical tag dat verwijst naar de URL waar het al op staat, met als doel de inspanningen van sommige scrapers teniet te doen.
Hoewel niet alle scrapers de volledige html code gebruiken, zullen sommigen dat wel doen. Voor degenen die dat wel doen, zorgt deze canonical tag ervoor dat de versie van jouw site wordt beoordeeld als het “originele” stukje inhoud.
Imitatie is misschien wel een groot compliment voor jouw geschreven content, maar het is gewoon een probleem voor de gemiddelde webmaster, aangezien het zeer negatieve invloed kan hebben. Interne of externe duplicatie zal dus moeten worden opgelost!
We hebben onmiddellijk verbeteringen gezien op de websites van onze klanten nadat Google duplicate content uit hun index heeft laten verwijderen of nadat wij interne duplicatie hebben opgelost.. Het is daarom belangrijk om snel actie te ondernemen! Wil je hier hulp bij hebben, dan zijn we altijd bereid jou te helpen!




Ons team staat
voor je klaar

